
Research
Projects



Dario Rethage
Passionate about developing machine intelligence capable of understanding the real world
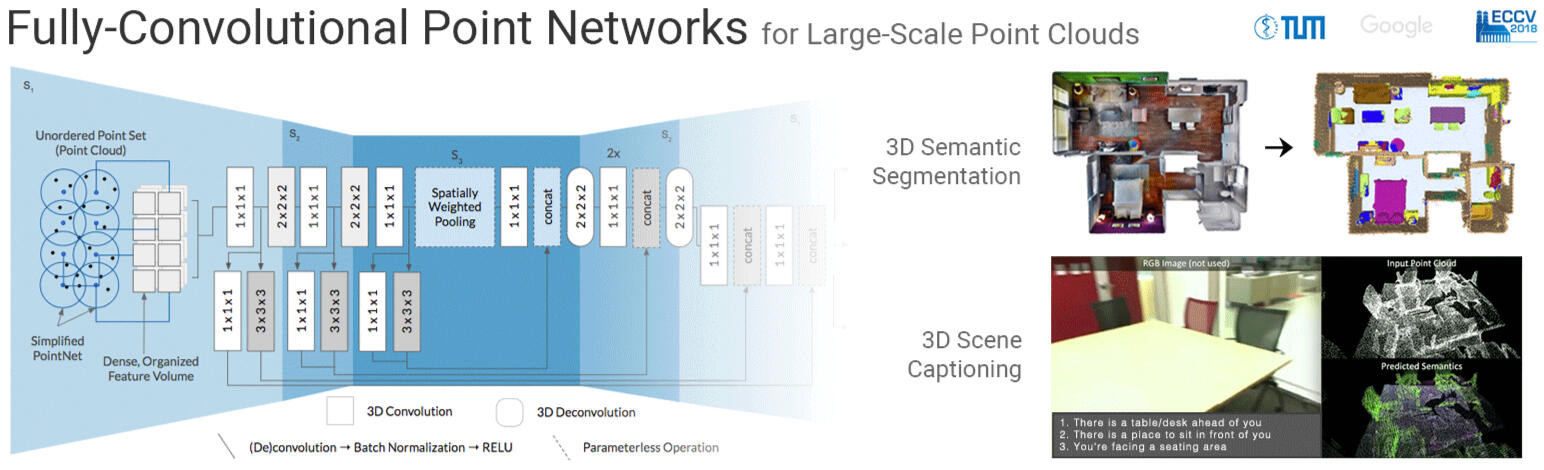
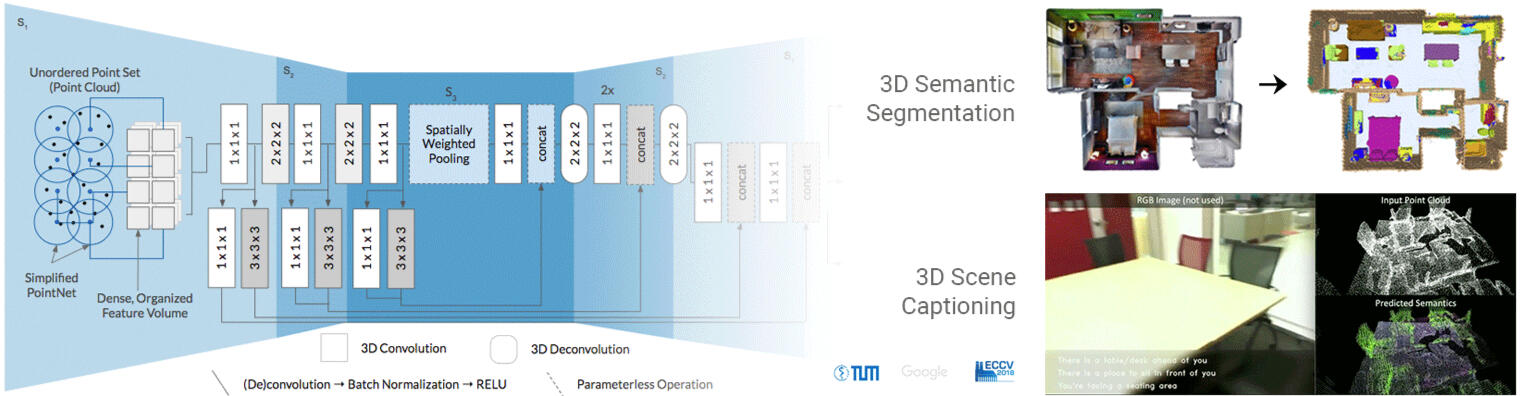
Fully-Convolutional Point Networks
Abstract
This work proposes a general-purpose, fully-convolutional network architecture for efficiently processing large-scale 3D data. One striking characteristic of our approach is its ability to process unorganized 3D representations such as point clouds as input, then transforming them internally to ordered structures to be processed via 3D convolutions. In contrast to conventional approaches that maintain either unorganized or organized representations, from input to output, our approach has the advantage of operating on memory efficient input data representations while at the same time exploiting the natural structure of convolutional operations to avoid the redundant computing and storing of spatial information in the network. The network eliminates the need to pre- or post process the raw sensor data. This, together with the fullyconvolutional nature of the network, makes it an end-to-end method able to process point clouds of huge spaces or even entire rooms with up to 200k points at once. Another advantage is that our network can produce either an ordered output or map predictions directly onto the input cloud, thus making it suitable as a general-purpose point cloud descriptor applicable to many 3D tasks. We demonstrate our network’s ability to effectively learn both low-level features as well as complex compositional relationships by evaluating it on benchmark datasets for semantic voxel segmentation, semantic part segmentation and 3D scene captioning.
Paper
Fully-Convolutional Point Networks for Large-Scale Point Clouds (D. Rethage, J. Wald, J. Sturm, N. Navab, F. Tombari) European Conference on Computer Vision (ECCV), 2018This work was done during my Master Thesis.
Code
The code accompanying this work and a trained model have been published at Github.
Supplementary Video

Dario Rethage
Passionate about developing machine intelligence capable of understanding the real world
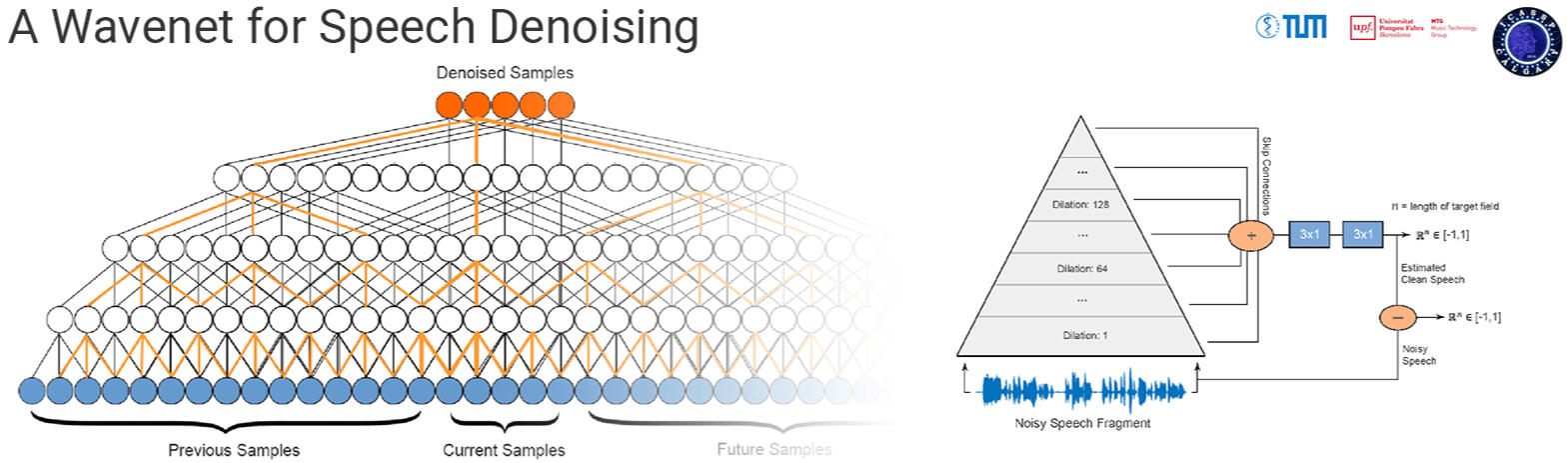
A Wavenet for Speech Denoising
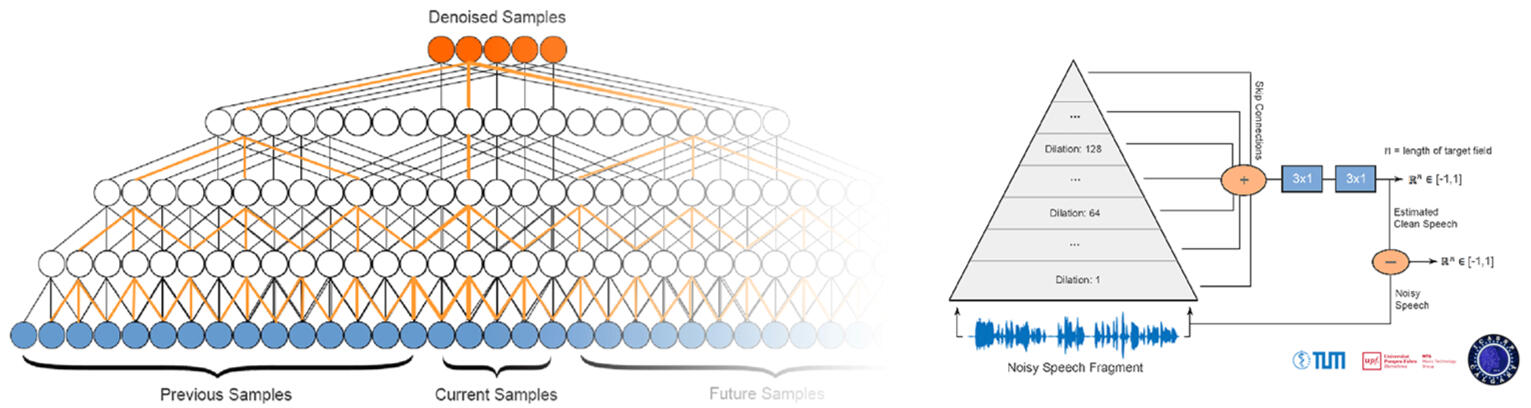
Abstract
Currently, most speech processing techniques use magnitude spectrograms as front-end and are therefore by default discarding part of the signal: the phase. In order to overcome this limitation, we propose an end-to-end learning method for speech denoising based on Wavenet. The proposed model adaptation retains Wavenet's powerful acoustic modeling capabilities, while significantly reducing its time-complexity by eliminating its autoregressive nature. Specifically, the model makes use of non-causal, dilated convolutions and predicts target fields instead of a single target sample. The discriminative adaptation of the model we propose, learns in a supervised fashion via minimizing a regression loss. These modifications make the model highly parallelizable during both training and inference. Both computational and perceptual evaluations indicate that the proposed method is preferred to Wiener filtering, a common method based on processing the magnitude spectrogram.
Paper
A Wavenet for Speech Denoising (D. Rethage, J. Pons, X. Serra) IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018
Code
The code accompanying this work and a trained model have been published at Github.
Audio Samples
Listen to denoised samples under varying noise conditions and SNRs here.

Dario Rethage
Passionate about developing machine intelligence capable of understanding the real world
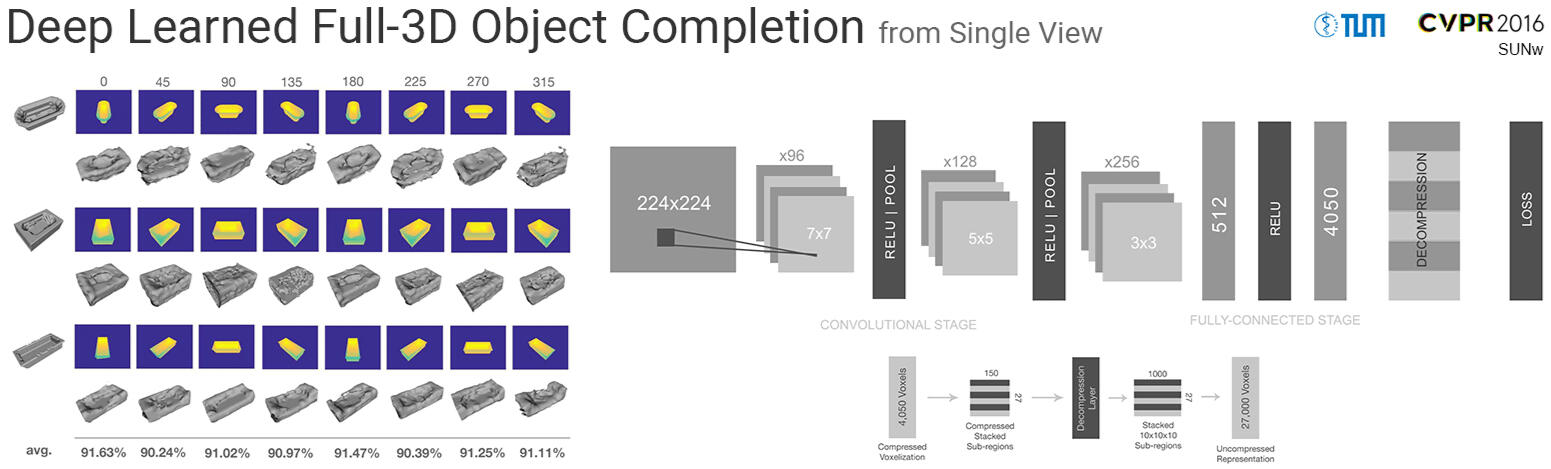
Deep Learned Full-3D Object Completion
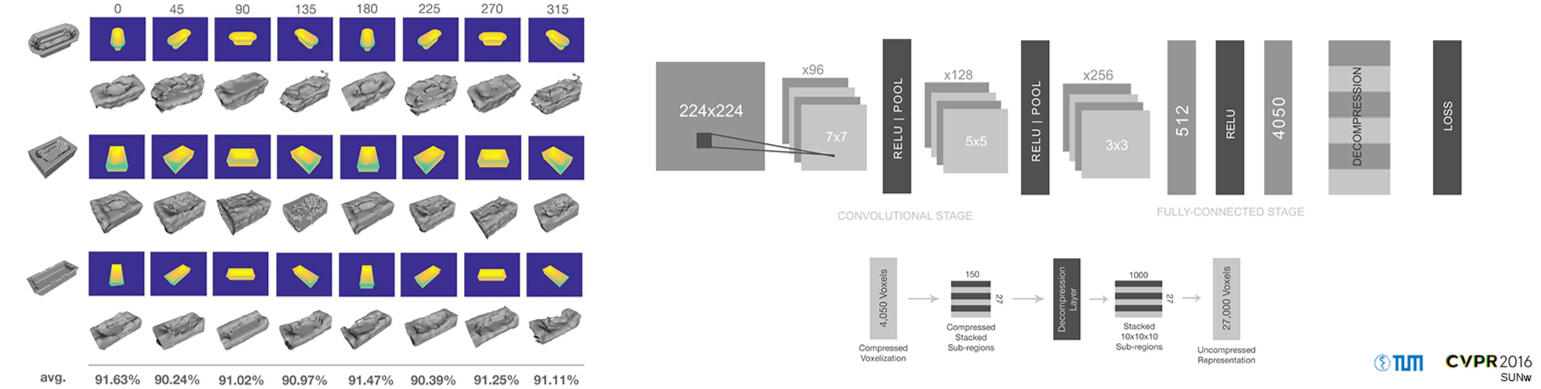
Abstract
3D geometry is a very informative cue when interacting with and navigating an environment. This writing proposes a new approach to 3D reconstruction and scene understanding, which implicitly learns 3D geometry from depth maps pairing a deep convolutional neural network architecture with an auto-encoder. A data set of synthetic depth views and voxelized 3D representations is built based on ModelNet, a large-scale collection of CAD models, to train networks. The proposed method offers a significant advantage over current, explicit reconstruction methods in that it learns key geometric features offline and makes use of those to predict the most probable reconstruction of an unseen object. The relatively small network, consisting of roughly 4 million weights, achieves a 92.9% reconstruction accuracy at a 30x30x30 resolution through the use of a pre-trained decompression layer. This is roughly 1/4 the weights of the current leading network. The fast execution time of the model makes it suitable for real-time applications.
Poster
An extended abstract of this work was presented at CVPR 2016's Scene Understanding Workshop.This work was done as an interdisciplinary project during my master program. The full report of this project with more visual examples can be found here.

Dario Rethage
Passionate about developing machine intelligence capable of understanding the real world
HandsOn
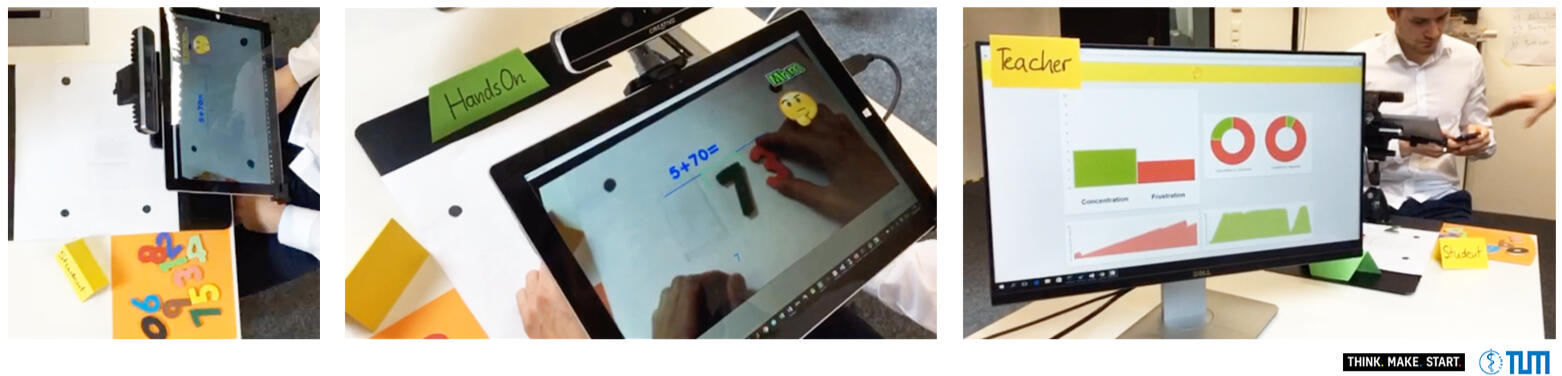
Description
HandsOn is an augmented reality (AR) learning tool designed for young children. It is an AR window that enables a visual, auditory and tactile learning experience to make learning more engaging. Using two optical cameras, the system is able to recognize physical objects used to complete tasks while simultaneously recognizing the student's facial expression to detect concentration and frustration. For example, physical numbers can be used to practice basic arithmetic as shown in the demo. The hardware and software for this demo was built during a one week startup bootcamp called Think. Make. Start.
Video

Dario Rethage
Passionate about developing machine intelligence capable of understanding the real world
Vision-Based Navigation for Flying Robots

Description
In this project, several human following algorithms were implemented and evaluated on a Parrot AR drone. Both marker-based and marker-less (using HOG descriptor) detection was evaluated. Algorithms were built on top of PTAM with a custom PID controller to provide control instructions to the drone. The drone successfully follows a human at a safe distance in unconstrained environments.